
Page 281 - A First Course In Stochastic Models
P. 281
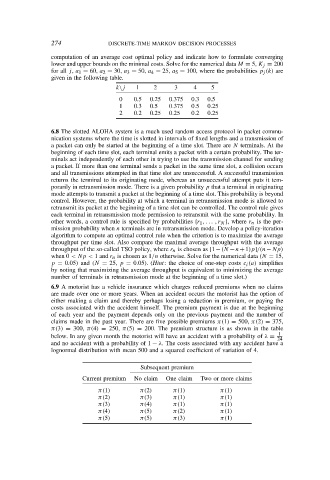
274 DISCRETE-TIME MARKOV DECISION PROCESSES
computation of an average cost optimal policy and indicate how to formulate converging
lower and upper bounds on the minimal costs. Solve for the numerical data M = 5, K j = 200
for all j, a 1 = 60, a 2 = 30, a 3 = 50, a 4 = 25, a 5 = 100, where the probabilities p j (k) are
given in the following table.
k\j 1 2 3 4 5
0 0.5 0.25 0.375 0.3 0.5
1 0.3 0.5 0.375 0.5 0.25
2 0.2 0.25 0.25 0.2 0.25
6.8 The slotted ALOHA system is a much used random access protocol in packet commu-
nication systems where the time is slotted in intervals of fixed lengths and a transmission of
a packet can only be started at the beginning of a time slot. There are N terminals. At the
beginning of each time slot, each terminal emits a packet with a certain probability. The ter-
minals act independently of each other in trying to use the transmission channel for sending
a packet. If more than one terminal sends a packet in the same time slot, a collision occurs
and all transmissions attempted in that time slot are unsuccessful. A successful transmission
returns the terminal to its originating mode, whereas an unsuccessful attempt puts it tem-
porarily in retransmission mode. There is a given probability p that a terminal in originating
mode attempts to transmit a packet at the beginning of a time slot. This probability is beyond
control. However, the probability at which a terminal in retransmission mode is allowed to
retransmit its packet at the beginning of a time slot can be controlled. The control rule gives
each terminal in retransmission mode permission to retransmit with the same probability. In
other words, a control rule is specified by probabilities {r 1 , . . . , r N }, where r n is the per-
mission probability when n terminals are in retransmission mode. Develop a policy-iteration
algorithm to compute an optimal control rule when the criterion is to maximize the average
throughput per time slot. Also compare the maximal average throughput with the average
throughput of the so-called TSO policy, where r n is chosen as [1−(N −n+1)p]/(n−Np)
when 0 < Np < 1 and r n is chosen as 1/n otherwise. Solve for the numerical data (N = 15,
p = 0.05) and (N = 25, p = 0.05). (Hint: the choice of one-step costs c i (a) simplifies
by noting that maximizing the average throughput is equivalent to minimizing the average
number of terminals in retransmission mode at the beginning of a time slot.)
6.9 A motorist has a vehicle insurance which charges reduced premiums when no claims
are made over one or more years. When an accident occurs the motorist has the option of
either making a claim and thereby perhaps losing a reduction in premium, or paying the
costs associated with the accident himself. The premium payment is due at the beginning
of each year and the payment depends only on the previous payment and the number of
claims made in the past year. There are five possible premiums π(1) = 500, π(2) = 375,
π(3) = 300, π(4) = 250, π(5) = 200. The premium structure is as shown in the table
1
below. In any given month the motorist will have an accident with a probability of λ = 24
and no accident with a probability of 1 − λ. The costs associated with any accident have a
lognormal distribution with mean 500 and a squared coefficient of variation of 4.
Subsequent premium
Current premium No claim One claim Two or more claims
π(1) π(2) π(1) π(1)
π(2) π(3) π(1) π(1)
π(3) π(4) π(1) π(1)
π(4) π(5) π(2) π(1)
π(5) π(5) π(3) π(1)