
Page 247 - ARM 64 Bit Assembly Language
P. 247
Integer mathematics 235
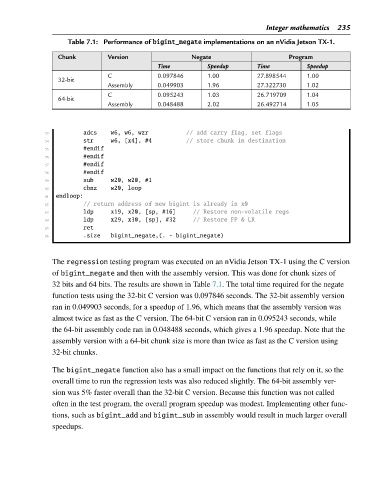
Table 7.1: Performance of bigint_negate implementations on an nVidia Jetson TX-1.
Chunk Version Negate Program
Time Speedup Time Speedup
C 0.097846 1.00 27.898544 1.00
32-bit
Assembly 0.049903 1.96 27.322730 1.02
C 0.095243 1.03 26.719709 1.04
64-bit
Assembly 0.048488 2.02 26.492714 1.05
53 adcs w6, w6, wzr // add carry flag, set flags
54 str w6, [x4], #4 // store chunk in destination
55 #endif
56 #endif
57 #endif
58 #endif
59 sub w20, w20, #1
60 cbnz w20, loop
61 endloop:
62 // return address of new bigint is already in x0
63 ldp x19, x20, [sp, #16] // Restore non-volatile regs
64 ldp x29, x30, [sp], #32 // Restore FP & LR
65 ret
66 .size bigint_negate,(. - bigint_negate)
The regression testing program was executed on an nVidia Jetson TX-1 using the C version
of bigint_negate and then with the assembly version. This was done for chunk sizes of
32 bits and 64 bits. The results are shown in Table 7.1. The total time required for the negate
function tests using the 32-bit C version was 0.097846 seconds. The 32-bit assembly version
ran in 0.049903 seconds, for a speedup of 1.96, which means that the assembly version was
almost twice as fast as the C version. The 64-bit C version ran in 0.095243 seconds, while
the 64-bit assembly code ran in 0.048488 seconds, which gives a 1.96 speedup. Note that the
assembly version with a 64-bit chunk size is more than twice as fast as the C version using
32-bit chunks.
The bigint_negate function also has a small impact on the functions that rely on it, so the
overall time to run the regression tests was also reduced slightly. The 64-bit assembly ver-
sion was 5% faster overall than the 32-bit C version. Because this function was not called
often in the test program, the overall program speedup was modest. Implementing other func-
tions, such as bigint_add and bigint_sub in assembly would result in much larger overall
speedups.