
Page 143 - Handbook of Deep Learning in Biomedical Engineering Techniques and Applications
P. 143
132 Chapter 5 Depression discovery in cancer communities using deep learning
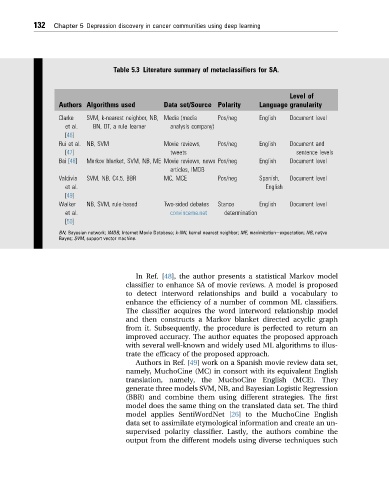
Table 5.3 Literature summary of metaclassifiers for SA.
Level of
Authors Algorithms used Data set/Source Polarity Language granularity
Clarke SVM, k-nearest neighbor, NB, Media (media Pos/neg English Document level
et al. BN, DT, a rule learner analysis company)
[46]
Rui et al. NB, SVM Movie reviews, Pos/neg English Document and
[47] tweets sentence levels
Bai [48] Markov blanket, SVM, NB, ME Movie reviews, news Pos/neg English Document level
articles, IMDB
Valdivia SVM, NB, C4.5, BBR MC, MCE Pos/neg Spanish, Document level
et al. English
[49]
Walker NB, SVM, rule-based Two-sided debates Stance English Document level
et al. convinceme.net determination
[50]
BN, Bayesian network; IMDB, Internet Movie Database; k-NN, kernel nearest neighbor; ME, maximizationeexpectation; NB, naþve
Bayes; SVM, support vector machine.
In Ref. [48], the author presents a statistical Markov model
classifier to enhance SA of movie reviews. A model is proposed
to detect interword relationships and build a vocabulary to
enhance the efficiency of a number of common ML classifiers.
The classifier acquires the word interword relationship model
and then constructs a Markov blanket directed acyclic graph
from it. Subsequently, the procedure is perfected to return an
improved accuracy. The author equates the proposed approach
with several well-known and widely used ML algorithms to illus-
trate the efficacy of the proposed approach.
Authors in Ref. [49] work on a Spanish movie review data set,
namely, MuchoCine (MC) in consort with its equivalent English
translation, namely, the MuchoCine English (MCE). They
generate three models SVM, NB, and Bayesian Logistic Regression
(BBR) and combine them using different strategies. The first
model does the same thing on the translated data set. The third
model applies SentiWordNet [26] to the MuchoCine English
data set to assimilate etymological information and create an un-
supervised polarity classifier. Lastly, the authors combine the
output from the different models using diverse techniques such