
Page 20 - Handbook of Deep Learning in Biomedical Engineering Techniques and Applications
P. 20
8 Chapter 1 Congruence of deep learning in biomedical engineering
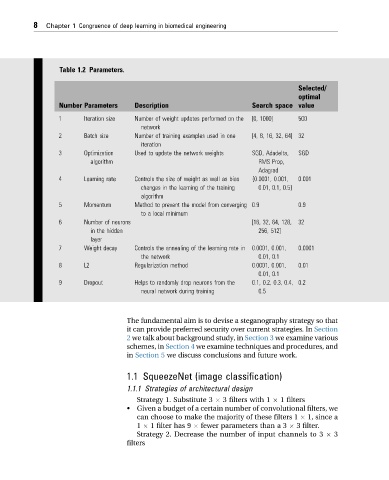
Table 1.2 Parameters.
Selected/
optimal
Number Parameters Description Search space value
1 Iteration size Number of weight updates performed on the [0, 1000] 500
network
2 Batch size Number of training examples used in one [4, 8, 16, 32, 64] 32
iteration
3 Optimization Used to update the network weights SGD, Adadelta, SGD
algorithm RMS Prop,
Adagrad
4 Learning rate Controls the size of weight as well as bias {0.0001, 0.001, 0.001
changes in the learning of the training 0.01, 0.1, 0.5}
algorithm
5 Momentum Method to prevent the model from converging 0.9 0.9
to a local minimum
6 Number of neurons [16, 32, 64, 128, 32
in the hidden 256, 512]
layer
7 Weight decay Controls the annealing of the learning rate in 0.0001, 0.001, 0.0001
the network 0.01, 0.1
8 L2 Regularization method 0.0001, 0.001, 0.01
0.01, 0.1
9 Dropout Helps to randomly drop neurons from the 0.1, 0.2, 0.3, 0.4, 0.2
neural network during training 0.5
The fundamental aim is to devise a steganography strategy so that
it can provide preferred security over current strategies. In Section
2 we talk about background study, in Section 3 we examine various
schemes, in Section 4 we examine techniques and procedures, and
in Section 5 we discuss conclusions and future work.
1.1 SqueezeNet (image classification)
1.1.1 Strategies of architectural design
Strategy 1. Substitute 3 3 filters with 1 1 filters
• Given a budget of a certain number of convolutional filters, we
can choose to make the majority of these filters 1 1, since a
1 1 filter has 9 fewer parameters than a 3 3 filter.
Strategy 2. Decrease the number of input channels to 3 3
filters