
Page 32 -
P. 32
15 Evaluating multiple ideas in parallel during
error analysis
Your team has several ideas for improving the cat detector:
• Fix the problem of your algorithm recognizing dogs as cats.
• Fix the problem of your algorithm recognizing great cats (lions, panthers, etc.) as house
cats (pets).
• Improve the system’s performance on blurry images.
• …
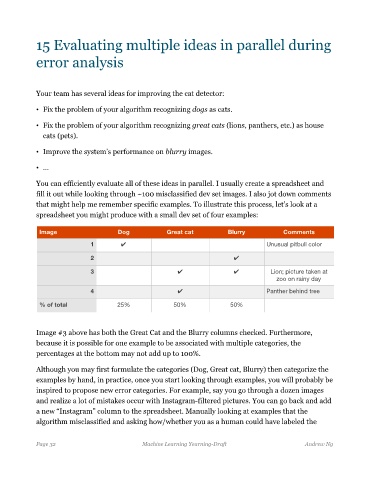
You can efficiently evaluate all of these ideas in parallel. I usually create a spreadsheet and
fill it out while looking through ~100 misclassified dev set images. I also jot down comments
that might help me remember specific examples. To illustrate this process, let’s look at a
spreadsheet you might produce with a small dev set of four examples:
Image Dog Great cat Blurry Comments
1 ✔ Unusual pitbull color
2 ✔
3 ✔ ✔ Lion; picture taken at
zoo on rainy day
4 ✔ Panther behind tree
% of total 25% 50% 50%
Image #3 above has both the Great Cat and the Blurry columns checked. Furthermore,
because it is possible for one example to be associated with multiple categories, the
percentages at the bottom may not add up to 100%.
Although you may first formulate the categories (Dog, Great cat, Blurry) then categorize the
examples by hand, in practice, once you start looking through examples, you will probably be
inspired to propose new error categories. For example, say you go through a dozen images
and realize a lot of mistakes occur with Instagram-filtered pictures. You can go back and add
a new “Instagram” column to the spreadsheet. Manually looking at examples that the
algorithm misclassified and asking how/whether you as a human could have labeled the
Page 32 Machine Learning Yearning-Draft Andrew Ng