
Page 121 - Machine Learning for Subsurface Characterization
P. 121
Shallow neural networks and classification methods Chapter 3 97
2
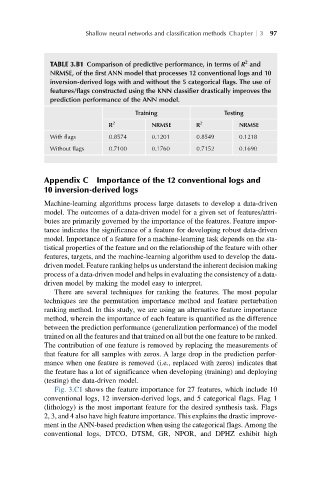
TABLE 3.B1 Comparison of predictive performance, in terms of R and
NRMSE, of the first ANN model that processes 12 conventional logs and 10
inversion-derived logs with and without the 5 categorical flags. The use of
features/flags constructed using the KNN classifier drastically improves the
prediction performance of the ANN model.
Training Testing
R 2 NRMSE R 2 NRMSE
With flags 0.8574 0.1201 0.8549 0.1218
Without flags 0.7100 0.1760 0.7152 0.1690
Appendix C Importance of the 12 conventional logs and
10 inversion-derived logs
Machine-learning algorithms process large datasets to develop a data-driven
model. The outcomes of a data-driven model for a given set of features/attri-
butes are primarily governed by the importance of the features. Feature impor-
tance indicates the significance of a feature for developing robust data-driven
model. Importance of a feature for a machine-learning task depends on the sta-
tistical properties of the feature and on the relationship of the feature with other
features, targets, and the machine-learning algorithm used to develop the data-
driven model. Feature ranking helps us understand the inherent decision making
process of a data-driven model and helps in evaluating the consistency of a data-
driven model by making the model easy to interpret.
There are several techniques for ranking the features. The most popular
techniques are the permutation importance method and feature perturbation
ranking method. In this study, we are using an alternative feature importance
method, wherein the importance of each feature is quantified as the difference
between the prediction performance (generalization performance) of the model
trained on all the features and that trained on all but the one feature to be ranked.
The contribution of one feature is removed by replacing the measurements of
that feature for all samples with zeros. A large drop in the prediction perfor-
mance when one feature is removed (i.e., replaced with zeros) indicates that
the feature has a lot of significance when developing (training) and deploying
(testing) the data-driven model.
Fig. 3.C1 shows the feature importance for 27 features, which include 10
conventional logs, 12 inversion-derived logs, and 5 categorical flags. Flag 1
(lithology) is the most important feature for the desired synthesis task. Flags
2, 3, and 4 also have high feature importance. This explains the drastic improve-
ment in the ANN-based prediction when using the categorical flags. Among the
conventional logs, DTCO, DTSM, GR, NPOR, and DPHZ exhibit high