
Page 250 - Machine Learning for Subsurface Characterization
P. 250
214 Machine learning for subsurface characterization
2
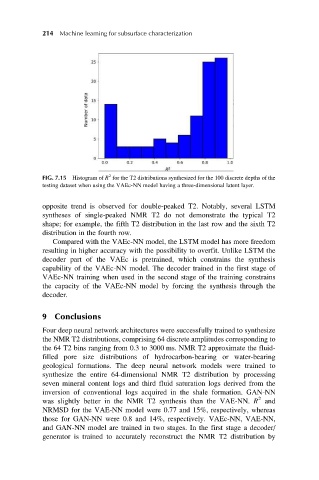
FIG. 7.15 Histogram of R for the T2 distributions synthesized for the 100 discrete depths of the
testing dataset when using the VAEc-NN model having a three-dimensional latent layer.
opposite trend is observed for double-peaked T2. Notably, several LSTM
syntheses of single-peaked NMR T2 do not demonstrate the typical T2
shape; for example, the fifth T2 distribution in the last row and the sixth T2
distribution in the fourth row.
Compared with the VAEc-NN model, the LSTM model has more freedom
resulting in higher accuracy with the possibility to overfit. Unlike LSTM the
decoder part of the VAEc is pretrained, which constrains the synthesis
capability of the VAEc-NN model. The decoder trained in the first stage of
VAEc-NN training when used in the second stage of the training constrains
the capacity of the VAEc-NN model by forcing the synthesis through the
decoder.
9 Conclusions
Four deep neural network architectures were successfully trained to synthesize
the NMR T2 distributions, comprising 64 discrete amplitudes corresponding to
the 64 T2 bins ranging from 0.3 to 3000 ms. NMR T2 approximate the fluid-
filled pore size distributions of hydrocarbon-bearing or water-bearing
geological formations. The deep neural network models were trained to
synthesize the entire 64-dimensional NMR T2 distribution by processing
seven mineral content logs and third fluid saturation logs derived from the
inversion of conventional logs acquired in the shale formation. GAN-NN
2
was slightly better in the NMR T2 synthesis than the VAE-NN. R and
NRMSD for the VAE-NN model were 0.77 and 15%, respectively, whereas
those for GAN-NN were 0.8 and 14%, respectively. VAEc-NN, VAE-NN,
and GAN-NN model are trained in two stages. In the first stage a decoder/
generator is trained to accurately reconstruct the NMR T2 distribution by