
Page 339 -
P. 339
322 Chapter 12 Dependability and security specification
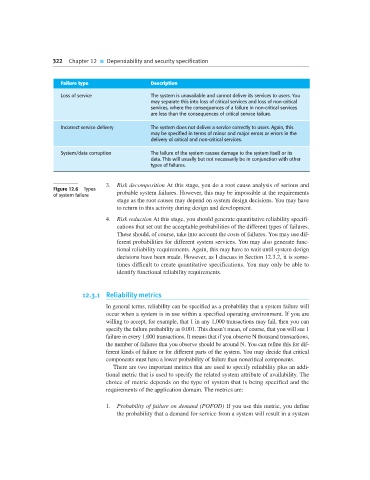
Failure type Description
Loss of service The system is unavailable and cannot deliver its services to users. You
may separate this into loss of critical services and loss of non-critical
services, where the consequences of a failure in non-critical services
are less than the consequences of critical service failure.
Incorrect service delivery The system does not deliver a service correctly to users. Again, this
may be specified in terms of minor and major errors or errors in the
delivery of critical and non-critical services.
System/data corruption The failure of the system causes damage to the system itself or its
data. This will usually but not necessarily be in conjunction with other
types of failures.
3. Risk decomposition At this stage, you do a root cause analysis of serious and
Figure 12.6 Types
of system failure probable system failures. However, this may be impossible at the requirements
stage as the root causes may depend on system design decisions. You may have
to return to this activity during design and development.
4. Risk reduction At this stage, you should generate quantitative reliability specifi-
cations that set out the acceptable probabilities of the different types of failures.
These should, of course, take into account the costs of failures. You may use dif-
ferent probabilities for different system services. You may also generate func-
tional reliability requirements. Again, this may have to wait until system design
decisions have been made. However, as I discuss in Section 12.3.2, it is some-
times difficult to create quantitative specifications. You may only be able to
identify functional reliability requirements.
12.3.1 Reliability metrics
In general terms, reliability can be specified as a probability that a system failure will
occur when a system is in use within a specified operating environment. If you are
willing to accept, for example, that 1 in any 1,000 transactions may fail, then you can
specify the failure probability as 0.001. This doesn’t mean, of course, that you will see 1
failure in every 1,000 transactions. It means that if you observe N thousand transactions,
the number of failures that you observe should be around N. You can refine this for dif-
ferent kinds of failure or for different parts of the system. You may decide that critical
components must have a lower probability of failure than noncritical components.
There are two important metrics that are used to specify reliability plus an addi-
tional metric that is used to specify the related system attribute of availability. The
choice of metric depends on the type of system that is being specified and the
requirements of the application domain. The metrics are:
1. Probability of failure on demand (POFOD) If you use this metric, you define
the probability that a demand for service from a system will result in a system