
Page 151 - Introduction to Statistical Pattern Recognition
P. 151
4 Parametric Classifiers 133
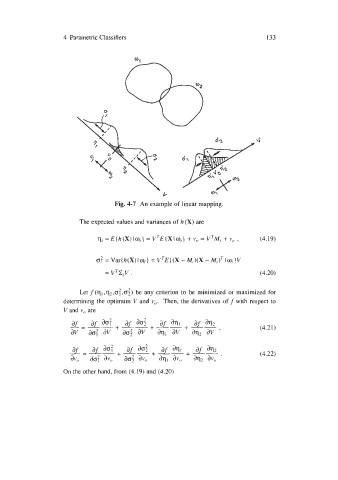
Fig. 4-7 An example of linear mapping.
The expected values and variances of h (X) are
q; = E(h(X)lw;} = VTE(Xlw;} + V(] = VTM; + v, , (4.19)
Let f (7-1 I ,q2,07,0i) be any criterion to be minimized or maximized for
determining the optimum V and v,. Then, the derivatives off with respect to
V and v, are
(4.21)
(4.22)
On the other hand, from (4.19) and (4.20)