
Page 156 - Introduction to Statistical Pattern Recognition
P. 156
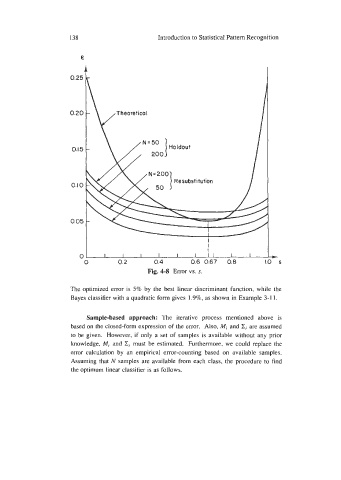
138 Introduction to Statistical Pattern Recognition
E
I
0.15
0.10
0.05
I
0 I I I I I I I I
0 0.2 0.4 0.6 0.67 0.8
Fig. 4-8 Error vs. s.
The optimized error is 5% by the best linear discriminant function, while the
Bayes classifier with a quadratic form gives 1.996, as shown in Example 3- 1 1.
Sample-based approach: The iterative process mentioned above is
based on the closed-form expression of the error. Also, Mi and Cj are assumed
to be given. However, if only a set of samples is available without any prior
knowledge, Mi and Zi must be estimated. Furthermore, we could replace the
error calculation by an empirical error-counting based on available samples.
Assuming that N samples are available from each class, the procedure to find
the optimum linear classifier is as follows.