
Page 328 - ARM 64 Bit Assembly Language
P. 328
Floating point 317
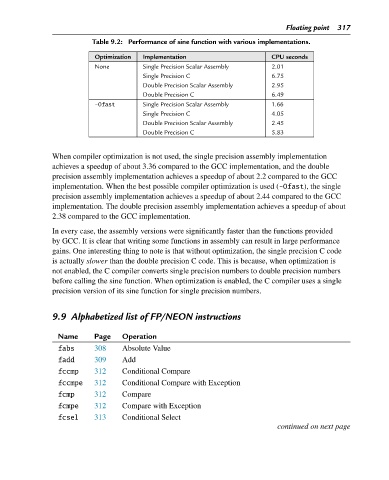
Table 9.2: Performance of sine function with various implementations.
Optimization Implementation CPU seconds
None Single Precision Scalar Assembly 2.01
Single Precision C 6.75
Double Precision Scalar Assembly 2.95
Double Precision C 6.49
-Ofast Single Precision Scalar Assembly 1.66
Single Precision C 4.05
Double Precision Scalar Assembly 2.45
Double Precision C 5.83
When compiler optimization is not used, the single precision assembly implementation
achieves a speedup of about 3.36 compared to the GCC implementation, and the double
precision assembly implementation achieves a speedup of about 2.2 compared to the GCC
implementation. When the best possible compiler optimization is used (-Ofast), the single
precision assembly implementation achieves a speedup of about 2.44 compared to the GCC
implementation. The double precision assembly implementation achieves a speedup of about
2.38 compared to the GCC implementation.
In every case, the assembly versions were significantly faster than the functions provided
by GCC. It is clear that writing some functions in assembly can result in large performance
gains. One interesting thing to note is that without optimization, the single precision C code
is actually slower than the double precision C code. This is because, when optimization is
not enabled, the C compiler converts single precision numbers to double precision numbers
before calling the sine function. When optimization is enabled, the C compiler uses a single
precision version of its sine function for single precision numbers.
9.9 Alphabetized list of FP/NEON instructions
Name Page Operation
fabs 308 Absolute Value
fadd 309 Add
fccmp 312 Conditional Compare
fccmpe 312 Conditional Compare with Exception
fcmp 312 Compare
fcmpe 312 Compare with Exception
fcsel 313 Conditional Select
continued on next page