
Page 217 - Classification Parameter Estimation & State Estimation An Engg Approach Using MATLAB
P. 217
206 FEATURE EXTRACTION AND SELECTION
The D N matrix W that maximizes the Bhattacharyya distance can be
derived as follows.
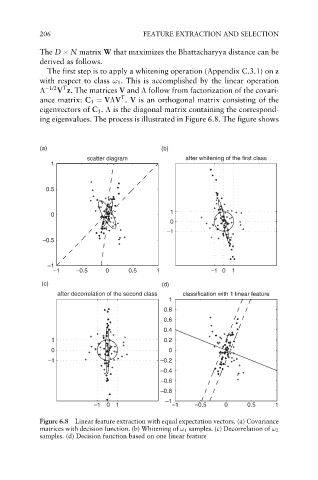
The first step is to apply a whitening operation (Appendix C.3.1) on z
with respect to class ! 1 . This is accomplished by the linear operation
T
1/2 V z. The matrices V and follow from factorization of the covari-
T
ance matrix: C 1 ¼ V V . V is an orthogonal matrix consisting of the
eigenvectors of C 1 . is the diagonal matrix containing the correspond-
ing eigenvalues. The process is illustrated in Figure 6.8. The figure shows
(a) (b)
scatter diagram after whitening of the first class
1
0.5
1
0
0
–1
–0.5
–1
–1 –0.5 0 0.5 1 –1 0 1
(c) (d)
after decorrelation of the second class classification with 1 linear feature
1
0.8
0.6
0.4
1 0.2
0 0
–1 –0.2
–0.4
–0.6
–0.8
–1
–1 0 1 –1 –0.5 0 0.5 1
Figure 6.8 Linear feature extraction with equal expectation vectors. (a) Covariance
matrices with decision function. (b) Whitening of ! 1 samples. (c) Decorrelation of ! 2
samples. (d) Decision function based on one linear feature