
Page 288 -
P. 288
3:20
2011/6/1
#9
Page 251
HAN 13-ch06-243-278-9780123814791
6.2 Frequent Itemset Mining Methods 251
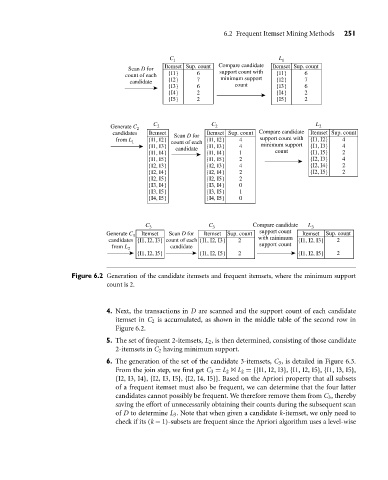
Figure 6.2 Generation of the candidate itemsets and frequent itemsets, where the minimum support
count is 2.
4. Next, the transactions in D are scanned and the support count of each candidate
itemset in C 2 is accumulated, as shown in the middle table of the second row in
Figure 6.2.
5. The set of frequent 2-itemsets, L 2 , is then determined, consisting of those candidate
2-itemsets in C 2 having minimum support.
6. The generation of the set of the candidate 3-itemsets, C 3 , is detailed in Figure 6.3.
From the join step, we first get C 3 = L 2 1 L 2 = {{I1, I2, I3}, {I1, I2, I5}, {I1, I3, I5},
{I2, I3, I4}, {I2, I3, I5}, {I2, I4, I5}}. Based on the Apriori property that all subsets
of a frequent itemset must also be frequent, we can determine that the four latter
candidates cannot possibly be frequent. We therefore remove them from C 3 , thereby
saving the effort of unnecessarily obtaining their counts during the subsequent scan
of D to determine L 3 . Note that when given a candidate k-itemset, we only need to
check if its (k − 1)-subsets are frequent since the Apriori algorithm uses a level-wise