
Page 92 - Handbook of Deep Learning in Biomedical Engineering Techniques and Applications
P. 92
80 Chapter 3 Application, algorithm, tools directly related to deep learning
Input gate: Addition of some useful information to the cell
state is mostly done by input gate. First, the information is gath-
ered using the sigmoid function and filters the remembered
values similar to the forget gate using inputs x(t) and h(t 1).
Then, a vector is obtained using tan h function that gives output
from 1to þ1, which contains all the possible values from x(t)
and h(t 1). Finally, the values of the vector and the regulated
values are multiplied to obtain the useful information [19].
Output gate: The work of extracting beneficial information
from the current cell state is treated as an output. First, a vector
is generated by using tan h function on the cell. Then, the infor-
mation is regulated using the various sigmoid function and filters
all the rest of the values to be remembered using inputs x(t) and
h(t 1). Finally, the values of the vector and the regulated values
are multiplied to produce output and input to the next cell [19].
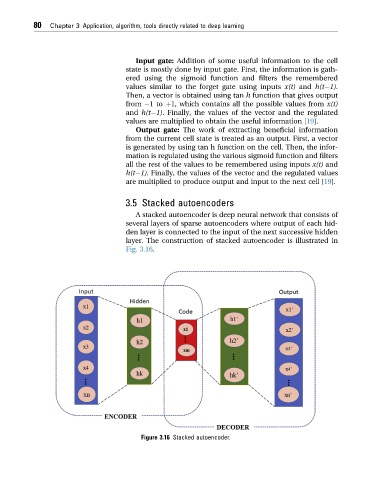
3.5 Stacked autoencoders
A stacked autoencoder is deep neural network that consists of
several layers of sparse autoencoders where output of each hid-
den layer is connected to the input of the next successive hidden
layer. The construction of stacked autoencoder is illustrated in
Fig. 3.16.
Figure 3.16 Stacked autoencoder.