
Page 52 -
P. 52
26 Error analysis on the training set
Your algorithm must perform well on the training set before you can expect it to perform
well on the dev/test sets.
In addition to the techniques described earlier to address high bias, I sometimes also carry
out an error analysis on the training data, following a protocol similar to error analysis on
the Eyeball dev set. This can be useful if your algorithm has high bias—i.e., if it is not fitting
the training set well.
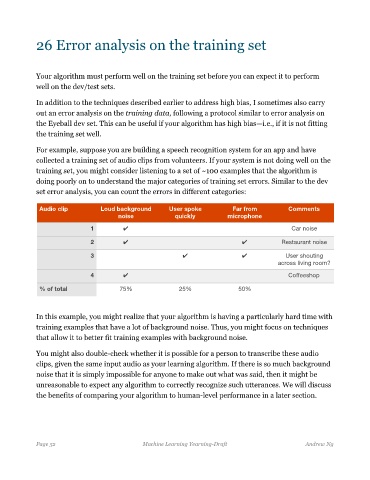
For example, suppose you are building a speech recognition system for an app and have
collected a training set of audio clips from volunteers. If your system is not doing well on the
training set, you might consider listening to a set of ~100 examples that the algorithm is
doing poorly on to understand the major categories of training set errors. Similar to the dev
set error analysis, you can count the errors in different categories:
Audio clip Loud background User spoke Far from Comments
noise quickly microphone
1 ✔ Car noise
2 ✔ ✔ Restaurant noise
3 ✔ ✔ User shouting
across living room?
4 ✔ Coffeeshop
% of total 75% 25% 50%
In this example, you might realize that your algorithm is having a particularly hard time with
training examples that have a lot of background noise. Thus, you might focus on techniques
that allow it to better fit training examples with background noise.
You might also double-check whether it is possible for a person to transcribe these audio
clips, given the same input audio as your learning algorithm. If there is so much background
noise that it is simply impossible for anyone to make out what was said, then it might be
unreasonable to expect any algorithm to correctly recognize such utterances. We will discuss
the benefits of comparing your algorithm to human-level performance in a later section.
Page 52 Machine Learning Yearning-Draft Andrew Ng