
Page 93 -
P. 93
48 More end-to-end learning examples
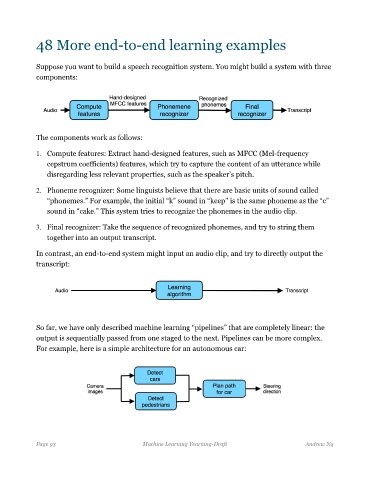
Suppose you want to build a speech recognition system. You might build a system with three
components:
The components work as follows:
1. Compute features: Extract hand-designed features, such as MFCC (Mel-frequency
cepstrum coefficients) features, which try to capture the content of an utterance while
disregarding less relevant properties, such as the speaker’s pitch.
2. Phoneme recognizer: Some linguists believe that there are basic units of sound called
“phonemes.” For example, the initial “k” sound in “keep” is the same phoneme as the “c”
sound in “cake.” This system tries to recognize the phonemes in the audio clip.
3. Final recognizer: Take the sequence of recognized phonemes, and try to string them
together into an output transcript.
In contrast, an end-to-end system might input an audio clip, and try to directly output the
transcript:
So far, we have only described machine learning “pipelines” that are completely linear: the
output is sequentially passed from one staged to the next. Pipelines can be more complex.
For example, here is a simple architecture for an autonomous car:
Page 93 Machine Learning Yearning-Draft Andrew Ng