
Page 122 -
P. 122
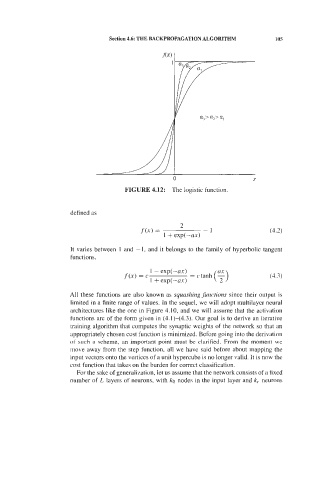
4.3 Model-Free Techni~ues 109
The Parzen window and k-nearest neighbour methods, to be explained in the
following sections, are both based on the idea of estimating the pdf of the pattern
distributions. The ROC curve method is a completely model-free method for two-
class situations, which simply addresses the problem of choosing the best
discriminating thresholds as a compromise in conflicting cost requirements.
The methods incorporating pdf estimation assume well-behaved, smooth
distributions, such that the probability density p(x) at point x can be estimated by
considering a sufficiently small region R with volume V, centred at x, as follows:
Imagine that one has a training set of n patterns and that k of these patterns fall
in the region R. The second hand integral of (4-31) then represents the number of
patterns falling inside R, therefore we obtain the estimate:
If the volume is too small compared to the number of samples, we will obtain
quite erratic estimates with a high variance. If it is too big so that it encloses a large
number of samples, we will obtain a smoothing effect since our point estimate will
depend on distant samples. These conflicting requirements can be addressed in two
ways:
1. Fix the volume so that it is inversely dependent on the number of available
points, i.e., the more points there are, the smaller is the volume. Compute k from
the data. This leads to the so-called kernel-based approaches such as the Parzen
window method.
2. Fix k depending on the number of points and compute V from the data. This
leads to the k-nearest neighbour method.
Usually the model-free techniques are only used in low dimensional situations.
Estimation of a pdf is a rather difficult issue in high-dimensional spaces, and ROC
analysis in this situation also requires burdensome compulations for a large number
of combinations of thresholds.
It is worth noting that pdf estimation in high dimensional spaces suffers from the
curse of dirnensionalify already discussed in section 2.6. Going back to the
argument presented in that section, concerning the partitioning of the feature space
into m~ypercubes, it is understandable that in order to obtain a reliable pdf
estimate we need to select a sufficiently high number rn of intervals along each
dimension, and have at least one point in each hypercube. Hence, the training set
size required for accurate pdf estimation will grow exponentially with d.
Model-free techniques come at a cost. First of all, no design formulas are
available; therefore, a trial and error strategy often has to be employed in order to
obtain a "best" solution. Second, dimensionality ratio, performance and