
Page 54 - The Art of Designing Embedded Systems
P. 54
Stop Writing Big Programs 41
frame, one CPU, one program, is doing many disparate activities that only
eventually serve a common goal.
Not enough horsepower? Toss in a 32-bitter. Crank up the clock rate.
Cut out wait states.
Why do we continue to emulate the antiquated notion of “big iron”-
even if the central machine is only an 805 l? Mainframes were long ago re-
placed by distributed workstations.
A single big CPU running the entire application implies that there’s
a huge program handling everything. We know that big programs are
bad-they cost too much to develop.
It’s usually cheaper to add more CPUs merely for the sake of simpli-
fying the software.
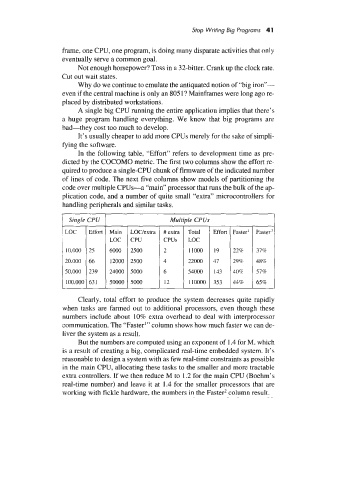
In the following table, “Effort” refers to development time as pre-
dicted by the COCOMO metric. The first two columns show the effort re-
quired to produce a single-CPU chunk of firmware of the indicated number
of lines of code. The next five columns show models of partitioning the
code over multiple CPUs-a “main” processor that runs the bulk of the ap-
plication code, and a number of quite small “extra” microcontrollers for
handling peripherals and similar tasks.
Single CPU Multiple CPUs
#extra Total Effort Faster I Faster’
10.000 25 229 379,
20.000 66 22000 29%
50,000 239 54000 133 40%
631
100,000
12
1 11oooo 353 44% 65%
Clearly, total effort to produce the system decreases quite rapidly
when tasks are farmed out to additional processors, even though these
numbers include about 10% extra overhead to deal with interprocessor
communication. The “Faster’” column shows how much faster we can de-
liver the system as a result.
But the numbers are computed using an exponent of 1.4 for M, which
is a result of creating a big, complicated real-time embedded system. It’s
reasonable to design a system with as few real-time constraints as possible
in the main CPU, allocating these tasks to the smaller and more tractable
extra controllers. If we then reduce M to 1.2 for the main CPU (Boehm’s
real-time number) and leave it at 1.4 for the smaller processors that are
working with fickle hardware. the numbers in the Faster2 column result.