
Page 143 - Data Architecture
P. 143
Chapter 4.3: Parallel Processing
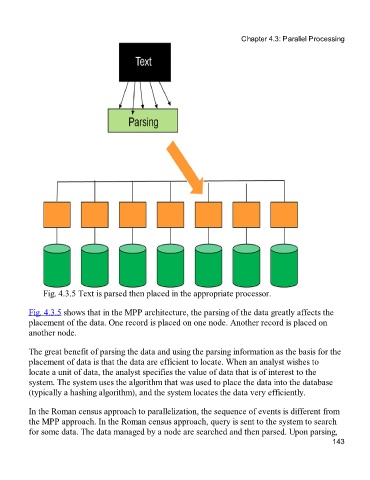
Fig. 4.3.5 Text is parsed then placed in the appropriate processor.
Fig. 4.3.5 shows that in the MPP architecture, the parsing of the data greatly affects the
placement of the data. One record is placed on one node. Another record is placed on
another node.
The great benefit of parsing the data and using the parsing information as the basis for the
placement of data is that the data are efficient to locate. When an analyst wishes to
locate a unit of data, the analyst specifies the value of data that is of interest to the
system. The system uses the algorithm that was used to place the data into the database
(typically a hashing algorithm), and the system locates the data very efficiently.
In the Roman census approach to parallelization, the sequence of events is different from
the MPP approach. In the Roman census approach, query is sent to the system to search
for some data. The data managed by a node are searched and then parsed. Upon parsing,
143