
Page 145 - Data Architecture
P. 145
Chapter 4.3: Parallel Processing
It is seen from Fig. 4.3.6 that in order to find a single instance of data, quite a bit of work
has to be done by the system. But, given that there are lots of processors, the elapsed
time to do the search can be cut into a reasonable amount of time. If it were not for
parallelism, the amount of time to do a search would be abhorrent.
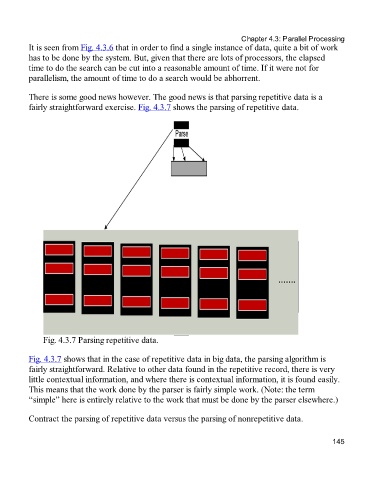
There is some good news however. The good news is that parsing repetitive data is a
fairly straightforward exercise. Fig. 4.3.7 shows the parsing of repetitive data.
Fig. 4.3.7 Parsing repetitive data.
Fig. 4.3.7 shows that in the case of repetitive data in big data, the parsing algorithm is
fairly straightforward. Relative to other data found in the repetitive record, there is very
little contextual information, and where there is contextual information, it is found easily.
This means that the work done by the parser is fairly simple work. (Note: the term
“simple” here is entirely relative to the work that must be done by the parser elsewhere.)
Contract the parsing of repetitive data versus the parsing of nonrepetitive data.
145