
Page 147 - Data Architecture
P. 147
Chapter 4.3: Parallel Processing
works only for repetitive data, not nonrepetitive data. Once the index for the repetitive
data is created, it can be scanned much more efficiently than doing a full table scan.
Once the index is created, there no longer is a need to do a full table scan every time big
data needs to be searched.
Of course, the index must be maintained. Every time data are added to the big data
collection of repetitive data, an update to the index is required.
In addition, the designer must know what contextual information is available at the
moment of the building of the index.
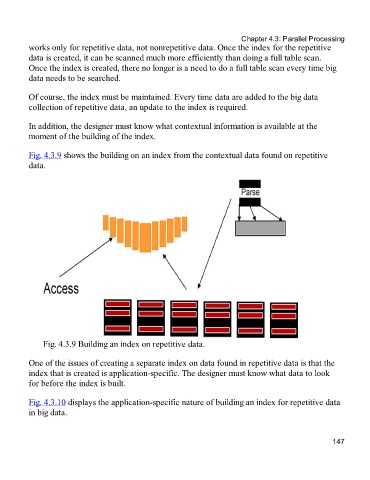
Fig. 4.3.9 shows the building on an index from the contextual data found on repetitive
data.
Fig. 4.3.9 Building an index on repetitive data.
One of the issues of creating a separate index on data found in repetitive data is that the
index that is created is application-specific. The designer must know what data to look
for before the index is built.
Fig. 4.3.10 displays the application-specific nature of building an index for repetitive data
in big data.
147