
Page 263 - Machine Learning for Subsurface Characterization
P. 263
Shallow and deep machine learning models Chapter 8 227
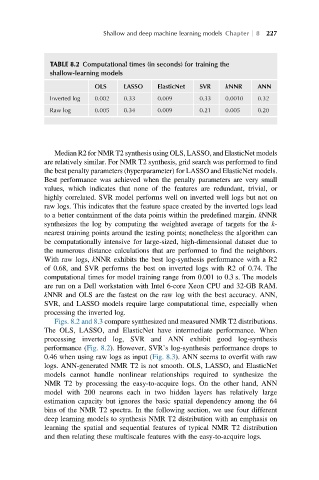
TABLE 8.2 Computational times (in seconds) for training the
shallow-learning models
OLS LASSO ElasticNet SVR kNNR ANN
Inverted log 0.002 0.33 0.009 0.33 0.0010 0.32
Raw log 0.005 0.34 0.009 0.21 0.005 0.20
Median R2 for NMR T2 synthesis using OLS, LASSO, and ElasticNet models
are relatively similar. For NMR T2 synthesis, grid search was performed to find
the best penalty parameters (hyperparameter) for LASSO and ElasticNet models.
Best performance was achieved when the penalty parameters are very small
values, which indicates that none of the features are redundant, trivial, or
highly correlated. SVR model performs well on inverted well logs but not on
raw logs. This indicates that the feature space created by the inverted logs lead
to a better containment of the data points within the predefined margin. kNNR
synthesizes the log by computing the weighted average of targets for the k-
nearest training points around the testing points; nonetheless the algorithm can
be computationally intensive for large-sized, high-dimensional dataset due to
the numerous distance calculations that are performed to find the neighbors.
With raw logs, kNNR exhibits the best log-synthesis performance with a R2
of 0.68, and SVR performs the best on inverted logs with R2 of 0.74. The
computational times for model training range from 0.001 to 0.3 s. The models
are run on a Dell workstation with Intel 6-core Xeon CPU and 32-GB RAM.
kNNR and OLS are the fastest on the raw log with the best accuracy. ANN,
SVR, and LASSO models require large computational time, especially when
processing the inverted log.
Figs. 8.2 and 8.3 compare synthesized and measured NMR T2 distributions.
The OLS, LASSO, and ElasticNet have intermediate performance. When
processing inverted log, SVR and ANN exhibit good log-synthesis
performance (Fig. 8.2). However, SVR’s log-synthesis performance drops to
0.46 when using raw logs as input (Fig. 8.3). ANN seems to overfit with raw
logs. ANN-generated NMR T2 is not smooth. OLS, LASSO, and ElasticNet
models cannot handle nonlinear relationships required to synthesize the
NMR T2 by processing the easy-to-acquire logs. On the other hand, ANN
model with 200 neurons each in two hidden layers has relatively large
estimation capacity but ignores the basic spatial dependency among the 64
bins of the NMR T2 spectra. In the following section, we use four different
deep learning models to synthesis NMR T2 distribution with an emphasis on
learning the spatial and sequential features of typical NMR T2 distribution
and then relating these multiscale features with the easy-to-acquire logs.