
Page 267 - Machine Learning for Subsurface Characterization
P. 267
Shallow and deep machine learning models Chapter 8 231
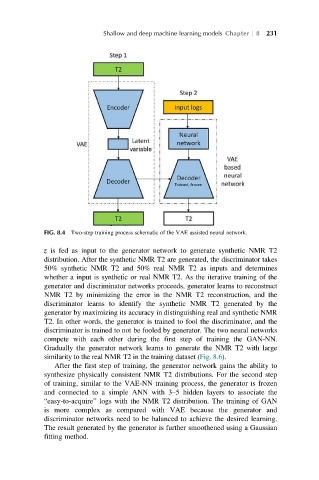
FIG. 8.4 Two-step training process schematic of the VAE assisted neural network.
z is fed as input to the generator network to generate synthetic NMR T2
distribution. After the synthetic NMR T2 are generated, the discriminator takes
50% synthetic NMR T2 and 50% real NMR T2 as inputs and determines
whether a input is synthetic or real NMR T2. As the iterative training of the
generator and discriminator networks proceeds, generator learns to reconstruct
NMR T2 by minimizing the error in the NMR T2 reconstruction, and the
discriminator learns to identify the synthetic NMR T2 generated by the
generator by maximizing its accuracy in distinguishing real and synthetic NMR
T2. In other words, the generator is trained to fool the discriminator, and the
discriminator is trained to not be fooled by generator. The two neural networks
compete with each other during the first step of training the GAN-NN.
Gradually the generator network learns to generate the NMR T2 with large
similarity to the real NMR T2 in the training dataset (Fig. 8.6).
After the first step of training, the generator network gains the ability to
synthesize physically consistent NMR T2 distributions. For the second step
of training, similar to the VAE-NN training process, the generator is frozen
and connected to a simple ANN with 3–5 hidden layers to associate the
“easy-to-acquire” logs with the NMR T2 distribution. The training of GAN
is more complex as compared with VAE because the generator and
discriminator networks need to be balanced to achieve the desired learning.
The result generated by the generator is further smoothened using a Gaussian
fitting method.