
Page 93 - Machine Learning for Subsurface Characterization
P. 93
Shallow neural networks and classification methods Chapter 3 77
2
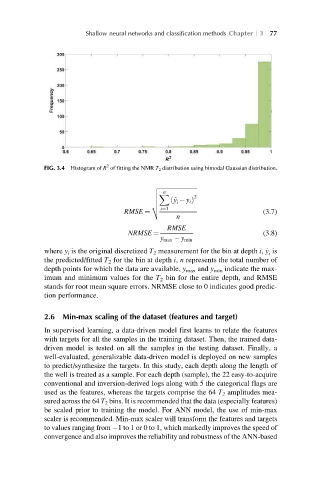
FIG. 3.4 Histogram of R of fitting the NMR T 2 distribution using bimodal Gaussian distribution.
v ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi
n
u
2
X
u
ð ^ y y i Þ
u i
t
i¼1
RMSE ¼ (3.7)
n
RMSE
NRMSE ¼ (3.8)
y max y min
where y i is the original discretized T 2 measurement for the bin at depth i, ^ y is
i
the predicted/fitted T 2 for the bin at depth i, n represents the total number of
depth points for which the data are available, y max and y min indicate the max-
imum and minimum values for the T 2 bin for the entire depth, and RMSE
stands for root mean square errors. NRMSE close to 0 indicates good predic-
tion performance.
2.6 Min-max scaling of the dataset (features and target)
In supervised learning, a data-driven model first learns to relate the features
with targets for all the samples in the training dataset. Then, the trained data-
driven model is tested on all the samples in the testing dataset. Finally, a
well-evaluated, generalizable data-driven model is deployed on new samples
to predict/synthesize the targets. In this study, each depth along the length of
the well is treated as a sample. For each depth (sample), the 22 easy-to-acquire
conventional and inversion-derived logs along with 5 the categorical flags are
used as the features, whereas the targets comprise the 64 T 2 amplitudes mea-
sured across the 64 T 2 bins. It is recommended that the data (especially features)
be scaled prior to training the model. For ANN model, the use of min-max
scaler is recommended. Min-max scaler will transform the features and targets
to values ranging from 1 to 1 or 0 to 1, which markedly improves the speed of
convergence and also improves the reliability and robustness of the ANN-based