
Page 159 - A Practical Guide from Design Planning to Manufacturing
P. 159
132 Chapter Five
Cycle 1 2 3 4 5 6 7 8
Div R2, R1 Fetch Decode Execute Write
Add R3, R2 Fetch Decode Wait Execute Write
Sub R8, R7 Fetch Decode Execute Write
Mul R4, R3 Fetch Decode Wait Execute Write
Sub R10, R9 Fetch Decode Execute Write
Sub R12, R11 Fetch Decode Execute
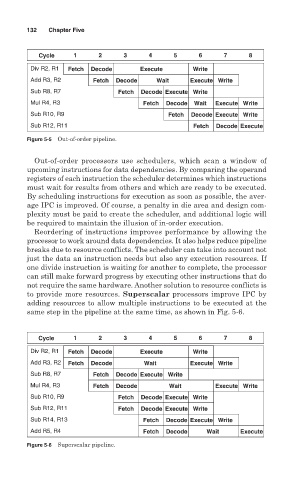
Figure 5-5 Out-of-order pipeline.
Out-of-order processors use schedulers, which scan a window of
upcoming instructions for data dependencies. By comparing the operand
registers of each instruction the scheduler determines which instructions
must wait for results from others and which are ready to be executed.
By scheduling instructions for execution as soon as possible, the aver-
age IPC is improved. Of course, a penalty in die area and design com-
plexity must be paid to create the scheduler, and additional logic will
be required to maintain the illusion of in-order execution.
Reordering of instructions improves performance by allowing the
processor to work around data dependencies. It also helps reduce pipeline
breaks due to resource conflicts. The scheduler can take into account not
just the data an instruction needs but also any execution resources. If
one divide instruction is waiting for another to complete, the processor
can still make forward progress by executing other instructions that do
not require the same hardware. Another solution to resource conflicts is
to provide more resources. Superscalar processors improve IPC by
adding resources to allow multiple instructions to be executed at the
same step in the pipeline at the same time, as shown in Fig. 5-6.
Cycle 1 2 3 4 5 6 7 8
Div R2, R1 Fetch Decode Execute Write
Add R3, R2 Fetch Decode Wait Execute Write
Sub R8, R7 Fetch Decode Execute Write
Mul R4, R3 Fetch Decode Wait Execute Write
Sub R10, R9 Fetch Decode Execute Write
Sub R12, R11 Fetch Decode Execute Write
Sub R14, R13 Fetch Decode Execute Write
Add R5, R4 Fetch Decode Wait Execute
Figure 5-6 Superscalar pipeline.