
Page 41 - ARM 64 Bit Assembly Language
P. 41
24 Chapter 1
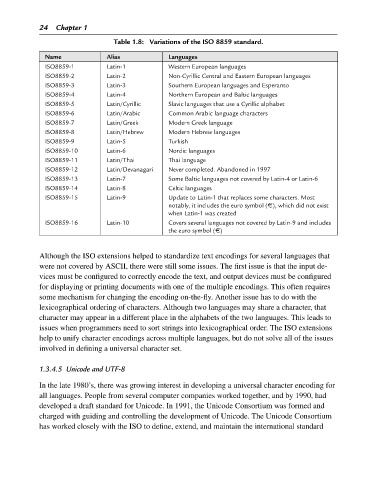
Table 1.8: Variations of the ISO 8859 standard.
Name Alias Languages
ISO8859-1 Latin-1 Western European languages
ISO8859-2 Latin-2 Non-Cyrillic Central and Eastern European languages
ISO8859-3 Latin-3 Southern European languages and Esperanto
ISO8859-4 Latin-4 Northern European and Baltic languages
ISO8859-5 Latin/Cyrillic Slavic languages that use a Cyrillic alphabet
ISO8859-6 Latin/Arabic Common Arabic language characters
ISO8859-7 Latin/Greek Modern Greek language
ISO8859-8 Latin/Hebrew Modern Hebrew languages
ISO8859-9 Latin-5 Turkish
ISO8859-10 Latin-6 Nordic languages
ISO8859-11 Latin/Thai Thai language
ISO8859-12 Latin/Devanagari Never completed. Abandoned in 1997
ISO8859-13 Latin-7 Some Baltic languages not covered by Latin-4 or Latin-6
ISO8859-14 Latin-8 Celtic languages
ISO8859-15 Latin-9 Update to Latin-1 that replaces some characters. Most
notably, it includes the euro symbol (e), which did not exist
when Latin-1 was created
ISO8859-16 Latin-10 Covers several languages not covered by Latin-9 and includes
the euro symbol (e)
Although the ISO extensions helped to standardize text encodings for several languages that
were not covered by ASCII, there were still some issues. The first issue is that the input de-
vices must be configured to correctly encode the text, and output devices must be configured
for displaying or printing documents with one of the multiple encodings. This often requires
some mechanism for changing the encoding on-the-fly. Another issue has to do with the
lexicographical ordering of characters. Although two languages may share a character, that
character may appear in a different place in the alphabets of the two languages. This leads to
issues when programmers need to sort strings into lexicographical order. The ISO extensions
help to unify character encodings across multiple languages, but do not solve all of the issues
involved in defining a universal character set.
1.3.4.5 Unicode and UTF-8
In the late 1980’s, there was growing interest in developing a universal character encoding for
all languages. People from several computer companies worked together, and by 1990, had
developed a draft standard for Unicode. In 1991, the Unicode Consortium was formed and
charged with guiding and controlling the development of Unicode. The Unicode Consortium
has worked closely with the ISO to define, extend, and maintain the international standard