
Page 42 - ARM 64 Bit Assembly Language
P. 42
Introduction 25
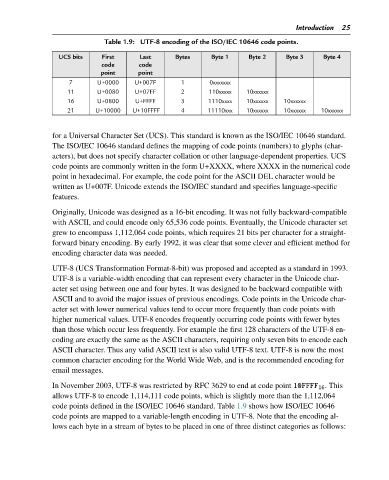
Table 1.9: UTF-8 encoding of the ISO/IEC 10646 code points.
UCS bits First Last Bytes Byte 1 Byte 2 Byte 3 Byte 4
code code
point point
7 U+0000 U+007F 1 0xxxxxxx
11 U+0080 U+07FF 2 110xxxxx 10xxxxxx
16 U+0800 U+FFFF 3 1110xxxx 10xxxxxx 10xxxxxx
21 U+10000 U+10FFFF 4 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
for a Universal Character Set (UCS). This standard is known as the ISO/IEC 10646 standard.
The ISO/IEC 10646 standard defines the mapping of code points (numbers) to glyphs (char-
acters), but does not specify character collation or other language-dependent properties. UCS
code points are commonly written in the form U+XXXX, where XXXX in the numerical code
point in hexadecimal. For example, the code point for the ASCII DEL character would be
written as U+007F. Unicode extends the ISO/IEC standard and specifies language-specific
features.
Originally, Unicode was designed as a 16-bit encoding. It was not fully backward-compatible
with ASCII, and could encode only 65,536 code points. Eventually, the Unicode character set
grew to encompass 1,112,064 code points, which requires 21 bits per character for a straight-
forward binary encoding. By early 1992, it was clear that some clever and efficient method for
encoding character data was needed.
UTF-8 (UCS Transformation Format-8-bit) was proposed and accepted as a standard in 1993.
UTF-8 is a variable-width encoding that can represent every character in the Unicode char-
acter set using between one and four bytes. It was designed to be backward compatible with
ASCII and to avoid the major issues of previous encodings. Code points in the Unicode char-
acter set with lower numerical values tend to occur more frequently than code points with
higher numerical values. UTF-8 encodes frequently occurring code points with fewer bytes
than those which occur less frequently. For example the first 128 characters of the UTF-8 en-
coding are exactly the same as the ASCII characters, requiring only seven bits to encode each
ASCII character. Thus any valid ASCII text is also valid UTF-8 text. UTF-8 is now the most
common character encoding for the World Wide Web, and is the recommended encoding for
email messages.
In November 2003, UTF-8 was restricted by RFC 3629 to end at code point 10FFFF 16 .This
allows UTF-8 to encode 1,114,111 code points, which is slightly more than the 1,112,064
code points defined in the ISO/IEC 10646 standard. Table 1.9 shows how ISO/IEC 10646
code points are mapped to a variable-length encoding in UTF-8. Note that the encoding al-
lows each byte in a stream of bytes to be placed in one of three distinct categories as follows: