
Page 284 - Big Data Analytics for Intelligent Healthcare Management
P. 284
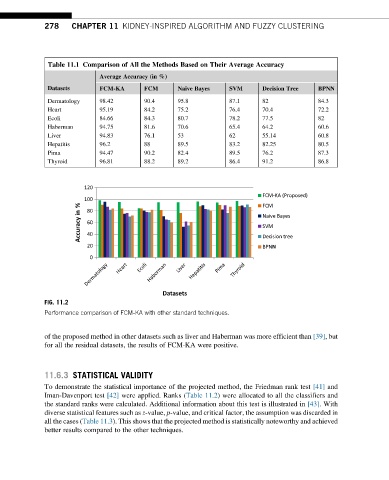
278 CHAPTER 11 KIDNEY-INSPIRED ALGORITHM AND FUZZY CLUSTERING
Table 11.1 Comparison of All the Methods Based on Their Average Accuracy
Average Accuracy (in %)
Datasets FCM-KA FCM Naive Bayes SVM Decision Tree BPNN
Dermatology 98.42 90.4 95.8 87.1 82 84.3
Heart 95.19 84.2 75.2 76.4 70.4 72.2
Ecoli 84.66 84.3 80.7 78.2 77.5 82
Haberman 94.75 81.6 70.6 65.4 64.2 60.6
Liver 94.83 76.1 53 62 55.14 60.8
Hepatitis 96.2 88 89.5 83.2 82.25 80.5
Pima 94.47 90.2 82.4 89.5 76.2 87.3
Thyroid 96.81 88.2 89.2 86.4 91.2 86.8
FIG. 11.2
Performance comparison of FCM-KA with other standard techniques.
of the proposed method in other datasets such as liver and Haberman was more efficient than [39], but
for all the residual datasets, the results of FCM-KA were positive.
11.6.3 STATISTICAL VALIDITY
To demonstrate the statistical importance of the projected method, the Friedman rank test [41] and
Iman-Davenport test [42] were applied. Ranks (Table 11.2) were allocated to all the classifiers and
the standard ranks were calculated. Additional information about this test is illustrated in [43]. With
diverse statistical features such as z-value, p-value, and critical factor, the assumption was discarded in
all the cases (Table 11.3). This shows that the projected method is statistically noteworthy and achieved
better results compared to the other techniques.