
Page 285 - Big Data Analytics for Intelligent Healthcare Management
P. 285
ACKNOWLEDGMENT 279
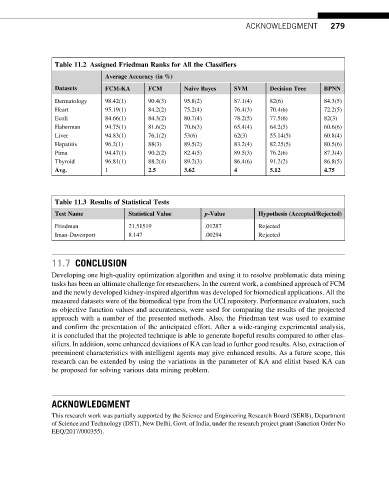
Table 11.2 Assigned Friedman Ranks for All the Classifiers
Average Accuracy (in %)
Datasets FCM-KA FCM Naive Bayes SVM Decision Tree BPNN
Dermatology 98.42(1) 90.4(3) 95.8(2) 87.1(4) 82(6) 84.3(5)
Heart 95.19(1) 84.2(2) 75.2(4) 76.4(3) 70.4(6) 72.2(5)
Ecoli 84.66(1) 84.3(2) 80.7(4) 78.2(5) 77.5(6) 82(3)
Haberman 94.75(1) 81.6(2) 70.6(3) 65.4(4) 64.2(5) 60.6(6)
Liver 94.83(1) 76.1(2) 53(6) 62(3) 55.14(5) 60.8(4)
Hepatitis 96.2(1) 88(3) 89.5(2) 83.2(4) 82.25(5) 80.5(6)
Pima 94.47(1) 90.2(2) 82.4(5) 89.5(3) 76.2(6) 87.3(4)
Thyroid 96.81(1) 88.2(4) 89.2(3) 86.4(6) 91.2(2) 86.8(5)
1
Avg. 2.5 3.62 4 5.12 4.75
Table 11.3 Results of Statistical Tests
Test Name Statistical Value p-Value Hypothesis (Accepted/Rejected)
Friedman 21.51519 .01287 Rejected
Iman-Davenport 8.147 .00294 Rejected
11.7 CONCLUSION
Developing one high-quality optimization algorithm and using it to resolve problematic data mining
tasks has been an ultimate challenge for researchers. In the current work, a combined approach of FCM
and the newly developed kidney-inspired algorithm was developed for biomedical applications. All the
measured datasets were of the biomedical type from the UCI repository. Performance evaluators, such
as objective function values and accurateness, were used for comparing the results of the projected
approach with a number of the presented methods. Also, the Friedman test was used to examine
and confirm the presentation of the anticipated effort. After a wide-ranging experimental analysis,
it is concluded that the projected technique is able to generate hopeful results compared to other clas-
sifiers. In addition, some enhanced deviations of KA can lead to further good results. Also, extraction of
preeminent characteristics with intelligent agents may give enhanced results. As a future scope, this
research can be extended by using the variations in the parameter of KA and elitist based KA can
be proposed for solving various data mining problem.
ACKNOWLEDGMENT
This research work was partially supported by the Science and Engineering Research Board (SERB), Department
of Science and Technology (DST), New Delhi, Govt. of India, under the research project grant (Sanction Order No
EEQ/2017/000355).