
Page 68 - Big Data Analytics for Intelligent Healthcare Management
P. 68
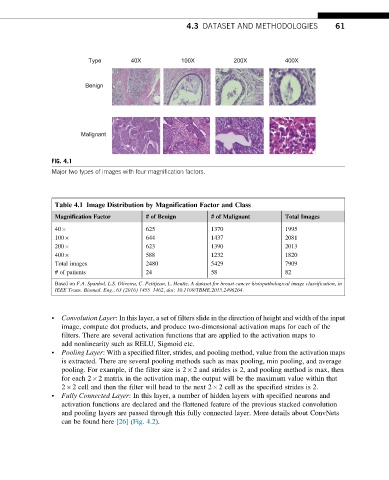
4.3 DATASET AND METHODOLOGIES 61
Type 40X 100X 200X 400X
Benign
Malignant
FIG. 4.1
Major two types of images with four magnification factors.
Table 4.1 Image Distribution by Magnification Factor and Class
Magnification Factor # of Benign # of Malignant Total Images
40 625 1370 1995
100 644 1437 2081
200 623 1390 2013
400 588 1232 1820
Total images 2480 5429 7909
# of patients 24 58 82
Based on F.A. Spanhol, L.S. Oliveira, C. Petitjean, L. Heutte, A dataset for breast cancer histopathological image classification, in
IEEE Trans. Biomed. Eng., 63 (2016) 1455–1462, doi: 10.1109/TBME.2015.2496264.
• Convolution Layer: In this layer, a set of filters slide in the direction of height and width of the input
image, compute dot products, and produce two-dimensional activation maps for each of the
filters. There are several activation functions that are applied to the activation maps to
add nonlinearity such as RELU, Sigmoid etc.
• Pooling Layer: With a specified filter, strides, and pooling method, value from the activation maps
is extracted. There are several pooling methods such as max pooling, min pooling, and average
pooling. For example, if the filter size is 2 2 and strides is 2, and pooling method is max, then
for each 2 2 matrix in the activation map, the output will be the maximum value within that
2 2 cell and then the filter will head to the next 2 2 cell as the specified strides is 2.
• Fully Connected Layer: In this layer, a number of hidden layers with specified neurons and
activation functions are declared and the flattened feature of the previous stacked convolution
and pooling layers are passed through this fully connected layer. More details about ConvNets
can be found here [26] (Fig. 4.2).