
Page 118 - Designing Sociable Robots
P. 118
breazeal-79017 book March 18, 2002 14:54
The Auditory System 99
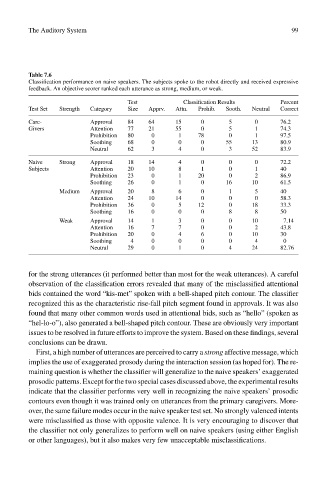
Table 7.6
Classification performance on naive speakers. The subjects spoke to the robot directly and received expressive
feedback. An objective scorer ranked each utterance as strong, medium, or weak.
Test Classification Results Percent
Test Set Strength Category Size Apprv. Attn. Prohib. Sooth. Neutral Correct
Care- Approval 84 64 15 0 5 0 76.2
Givers Attention 77 21 55 0 5 1 74.3
Prohibition 80 0 1 78 0 1 97.5
Soothing 68 0 0 0 55 13 80.9
Neutral 62 3 4 0 3 52 83.9
Naive Strong Approval 18 14 4 0 0 0 72.2
Subjects Attention 20 10 8 1 0 1 40
Prohibition 23 0 1 20 0 2 86.9
Soothing 26 0 1 0 16 10 61.5
Medium Approval 20 8 6 0 1 5 40
Attention 24 10 14 0 0 0 58.3
Prohibition 36 0 5 12 0 18 33.3
Soothing 16 0 0 0 8 8 50
Weak Approval 14 1 3 0 0 10 7.14
Attention 16 7 7 0 0 2 43.8
Prohibition 20 0 4 6 0 10 30
Soothing 4 0 0 0 0 4 0
Neutral 29 0 1 0 4 24 82.76
for the strong utterances (it performed better than most for the weak utterances). A careful
observation of the classification errors revealed that many of the misclassified attentional
bids contained the word “kis-met” spoken with a bell-shaped pitch contour. The classifier
recognized this as the characteristic rise-fall pitch segment found in approvals. It was also
found that many other common words used in attentional bids, such as “hello” (spoken as
“hel-lo-o”), also generated a bell-shaped pitch contour. These are obviously very important
issues to be resolved in future efforts to improve the system. Based on these findings, several
conclusions can be drawn.
First, a high number of utterances are perceived to carry a strong affective message, which
implies the use of exaggerated prosody during the interaction session (as hoped for). The re-
maining question is whether the classifier will generalize to the naive speakers’ exaggerated
prosodic patterns. Except for the two special cases discussed above, the experimental results
indicate that the classifier performs very well in recognizing the naive speakers’ prosodic
contours even though it was trained only on utterances from the primary caregivers. More-
over, the same failure modes occur in the naive speaker test set. No strongly valenced intents
were misclassified as those with opposite valence. It is very encouraging to discover that
the classifier not only generalizes to perform well on naive speakers (using either English
or other languages), but it also makes very few unacceptable misclassifications.