
Page 212 - Distributed model predictive control for plant-wide systems
P. 212
186 Distributed Model Predictive Control for Plant-Wide Systems
u 1
0
u 2
u 3
u 4
–0.5
u i
–1
–0.5
5 10 15 20
Time (s)
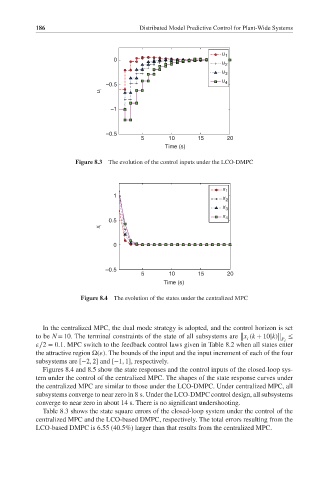
Figure 8.3 The evolution of the control inputs under the LCO-DMPC
x 1
1
x 2
x 3
x 4
0.5
x i
0
–0.5
5 10 15 20
Time (s)
Figure 8.4 The evolution of the states under the centralized MPC
In the centralized MPC, the dual mode strategy is adopted, and the control horizon is set
to be N = 10. The terminal constraints of the state of all subsystems are x (k + 10|k) ‖ ≤
‖
‖ i
‖P i
∕2 = 0.1. MPC switch to the feedback control laws given in Table 8.2 when all states enter
the attractive region Ω( ). The bounds of the input and the input increment of each of the four
subsystems are [−2, 2] and [−1, 1], respectively.
Figures 8.4 and 8.5 show the state responses and the control inputs of the closed-loop sys-
tem under the control of the centralized MPC. The shapes of the state response curves under
the centralized MPC are similar to those under the LCO-DMPC. Under centralized MPC, all
subsystems converge to near zero in 8 s. Under the LCO-DMPC control design, all subsystems
converge to near zero in about 14 s. There is no significant undershooting.
Table 8.3 shows the state square errors of the closed-loop system under the control of the
centralized MPC and the LCO-based DMPC, respectively. The total errors resulting from the
LCO-based DMPC is 6.55 (40.5%) larger than that results from the centralized MPC.