
Page 163 - Intelligent Digital Oil And Gas Fields
P. 163
Components of Artificial Intelligence and Data Analytics 125
sets because it requires the classes to be separable by a linear boundary. The
support vector classifier is an extension of a maximum margin classifier that
can be applied to a broader range of problems. Finally, the SVM is a further
extension and next-generation support vector classifier and can accommo-
date nonlinear class boundaries. These three terms are often loosely and
interchangeably used, but it is important to distinguish between them when
deploying the SVM method.
The mathematical details behind the derivation of both the maximum
margin classifier and the support vector classifier are beyond the scope of this
book; for more information see James et al. (2014) and Leskovec et al.
(2014). However, the main difference between the support vector classifier
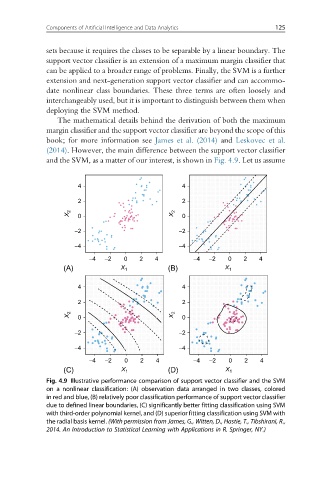
and the SVM, as a matter of our interest, is shown in Fig. 4.9. Let us assume
4 4
2 2
X 2 0 X 2 0
−2 −2
−4 −4
−4 −2 0 2 4 −4 −2 0 2 4
(A) X 1 (B) X 1
4 4
2 2
X 2 0 X 2 0
−2 −2
−4 −4
−4 −2 0 2 4 −4 −2 0 2 4
(C) X 1 (D) X 1
Fig. 4.9 Illustrative performance comparison of support vector classifier and the SVM
on a nonlinear classification: (A) observation data arranged in two classes, colored
in red and blue, (B) relatively poor classification performance of support vector classifier
due to defined linear boundaries, (C) significantly better fitting classification using SVM
with third-order polynomial kernel, and (D) superior fitting classification using SVM with
the radial basis kernel. (With permission from James, G., Witten, D., Hastie, T., Tibshirani, R.,
2014. An Introduction to Statistical Learning with Applications in R. Springer, NY.)