
Page 131 - Introduction to Statistical Pattern Recognition
P. 131
3 Hypothesis Testing 113
@--'(€) E %
4 4
0-
-1 -
-
-2
1
0.5
1 2 3 4 5 6 7 8 9 1 0 6
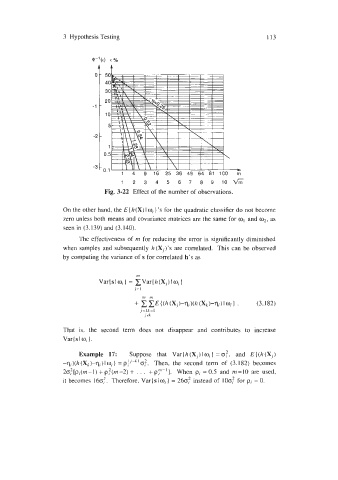
Fig. 3-22 Effect of the number of observations.
On the other hand, the E [ h(X) wi 1's for the quadratic classifier do not become
I
zero unless both means and covariance matrices are the same for o, and 02, as
seen in (3.139) and (3.140).
The effectiveness of m for reducing the error is significantly diminished
when samples and subsequently h(Xj)'s are correlated. This can be observed
by computing the variance of s for correlated h's as
ni
Var(sIoj) = zVar(h(X,i)loiJ
;=I
That is, the second term does not disappear and contributes to increase
Var{ s I mi 1.
Example 17: Suppose that Var{h(X,)Io,} =o:, and E((h(X,)
-q,)(h (Xk)-q,) I w, J = p I '-I ' 02. Then, the second term of (3.182) becomes
20![p,(m-l)+p,'(m-2) + . . . +p?-']. When p, =OS and m=10 are used,
it becomes 160:. Therefore, Var( s I w, ] = 260; instead of lMf for p, = 0.