
Page 375 - Carrahers_Polymer_Chemistry,_Eighth_Edition
P. 375
338 Carraher’s Polymer Chemistry
repeat units. The pendent groups react with the amino “ends” of the enzyme effectively coupling
or immobilizing the enzyme. Modifications of this procedure have been used to immobilize a
wide variety of enzymes. For instance, the particular reactive or anchoring group on the gel can
be especially modified for a particular enzyme. Spacers and variations in the active coupling end
are often employed. Amine groups on gels are easily modified to give other functional groups,
including alcohols, acids, nitriles, and acids. Recently, other entities, such as fungi, bacteria, and
cells have been immobilized successfully. This technique can be used for the continuous synthe-
sis of specifi c molecules.
10.3 NUCLEIC ACIDS
Nucleoproteins, which are conjugated proteins, may be separated into nucleic acids and proteins.
The name “nuclein,” which was coined by Miescher in 1869 to describe products isolated form
nuclei in pus, was later changed to nucleic acid. Somewhat pure nucleic acid was isolated by Levene
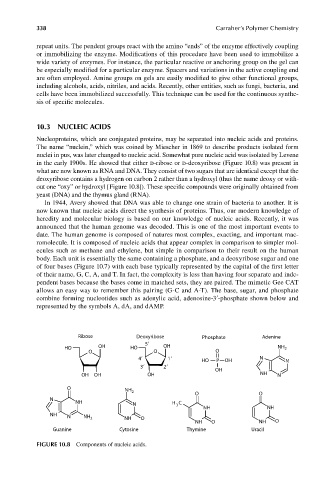
in the early 1900s. He showed that either d-ribose or d-deoxyribose (Figure 10.8) was present in
what are now known as RNA and DNA. They consist of two sugars that are identical except that the
deoxyribose contains a hydrogen on carbon 2 rather than a hydroxyl (thus the name deoxy or with-
out one “oxy” or hydroxyl [Figure 10.8]). These specific compounds were originally obtained from
yeast (DNA) and the thymus gland (RNA).
In 1944, Avery showed that DNA was able to change one strain of bacteria to another. It is
now known that nucleic acids direct the synthesis of proteins. Thus, our modern knowledge of
heredity and molecular biology is based on our knowledge of nucleic acids. Recently, it was
announced that the human genome was decoded. This is one of the most important events to
date. The human genome is composed of natures most complex, exacting, and important mac-
romolecule. It is composed of nucleic acids that appear complex in comparison to simpler mol-
ecules such as methane and ethylene, but simple in comparison to their result on the human
body. Each unit is essentially the same containing a phosphate, and a deoxyribose sugar and one
of four bases (Figure 10.7) with each base typically represented by the capital of the fi rst letter
of their name, G, C, A, and T. In fact, the complexity is less than having four separate and inde-
pendent bases because the bases come in matched sets, they are paired. The mimetic Gee CAT
allows an easy way to remember this pairing (G-C and A-T). The base, sugar, and phosphate
combine forming nucleotides such as adenylic acid, adenosine-3′-phosphate shown below and
represented by the symbols A, dA, and dAMP.
Ribose Deoxyribose Phosphate Adenine
5
HO OH HO OH NH 2
O O O
4 1 HO P OH N N
3 2
OH
OH OH OH NH N
O NH
2
O O
N
NH H C
N 3
NH NH
NH N NH
O
NH
2
NH O NH O
Guanine Cytosine Thymine Uracil
FIGURE 10.8 Components of nucleic acids.
9/14/2010 3:41:15 PM
K10478.indb 338 9/14/2010 3:41:15 PM
K10478.indb 338