
Page 304 -
P. 304
Section 9.3 Image Segmentation by Clustering Pixels 272
from the pixel. This means that one can produce rather more efficient algorithms
than the one we sketched, and there is a considerable literature of these algo-
rithms. In this literature, authors tend to criticize the watershed algorithm for
oversegmentation—that is, for producing “too many” segments. More recently,
watershed algorithms are quite widely used because they produce tolerable super-
pixels, and are efficient. Good implementations of watershed algorithms are widely
available; to produce Figure 9.16, we used the implementation in Matlab’s Image
processing toolbox. It is natural to use the gradient magnitude to drive a watershed
transform, because this divides the image up into regions of relatively small gradi-
ent; however, one could also use the image intensity, in which case each region is the
domain of attraction of an intensity minimum or maximum. Gradient watersheds
tend to produce more useful superpixels (Figure 9.16).
9.3.3 Segmentation Using K-means
There is a strong resonance between image segmentation as we have described
it, and vector quantization. In Chapter 6, we described vector quantization in
the context of texture representation and introduced the k-means algorithm. K-
means produces good image segments for some applications. Following the general
recipe, we compute a feature vector representing each pixel, we apply k-means, and
each pixel goes to the segment represented by the cluster center that claims its
feature vector. The main consequence of using k-means is that we know how many
segments there will be. For some applications, this is a good thing; for example,
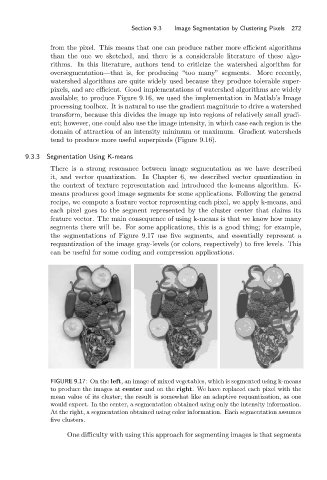
the segmentations of Figure 9.17 use five segments, and essentially represent a
requantization of the image gray-levels (or colors, respectively) to five levels. This
can be useful for some coding and compression applications.
FIGURE 9.17: On the left, an image of mixed vegetables, which is segmented using k-means
to produce the images at center andonthe right. We have replaced each pixel with the
mean value of its cluster; the result is somewhat like an adaptive requantization, as one
would expect. In the center, a segmentation obtained using only the intensity information.
At the right, a segmentation obtained using color information. Each segmentation assumes
five clusters.
One difficulty with using this approach for segmenting images is that segments