
Page 188 - Master Handbook of Acoustics
P. 188
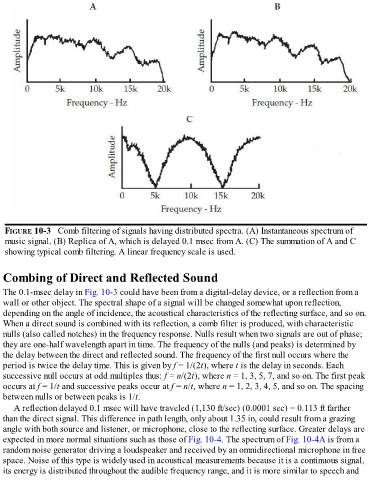
FIGURE 10-3 Comb filtering of signals having distributed spectra. (A) Instantaneous spectrum of
music signal. (B) Replica of A, which is delayed 0.1 msec from A. (C) The summation of A and C
showing typical comb filtering. A linear frequency scale is used.
Combing of Direct and Reflected Sound
The 0.1-msec delay in Fig. 10-3 could have been from a digital-delay device, or a reflection from a
wall or other object. The spectral shape of a signal will be changed somewhat upon reflection,
depending on the angle of incidence, the acoustical characteristics of the reflecting surface, and so on.
When a direct sound is combined with its reflection, a comb filter is produced, with characteristic
nulls (also called notches) in the frequency response. Nulls result when two signals are out of phase;
they are one-half wavelength apart in time. The frequency of the nulls (and peaks) is determined by
the delay between the direct and reflected sound. The frequency of the first null occurs where the
period is twice the delay time. This is given by f = 1/(2t), where t is the delay in seconds. Each
successive null occurs at odd multiples thus: f = n/(2t), where n = 1, 3, 5, 7, and so on. The first peak
occurs at f = 1/t and successive peaks occur at f = n/t, where n = 1, 2, 3, 4, 5, and so on. The spacing
between nulls or between peaks is 1/t.
A reflection delayed 0.1 msec will have traveled (1,130 ft/sec) (0.0001 sec) = 0.113 ft farther
than the direct signal. This difference in path length, only about 1.35 in, could result from a grazing
angle with both source and listener, or microphone, close to the reflecting surface. Greater delays are
expected in more normal situations such as those of Fig. 10-4. The spectrum of Fig. 10-4A is from a
random noise generator driving a loudspeaker and received by an omnidirectional microphone in free
space. Noise of this type is widely used in acoustical measurements because it is a continuous signal,
its energy is distributed throughout the audible frequency range, and it is more similar to speech and