
Page 26 - Introduction to Statistical Pattern Recognition
P. 26
8 Introduction to Statistical Pattern Recognition
SEARCH FOR
NORMALIZATION NEW MEASUREMENTS
REGISTRATION
(NONPARAMETRIC)
1
NONPARAMETRIC &< Eo ERROR ESTIMATION
PROCESS (NONPARAMETRIC)
STATISTICAL TESTS
LINEAR CLASSIFIER
QUADRATIC CLASSIFIER
PIECEWISE CLASSIFIER
PARAMETERIZATION NONPARAMETRIC CLASS1 FI E R
PROCESS
t
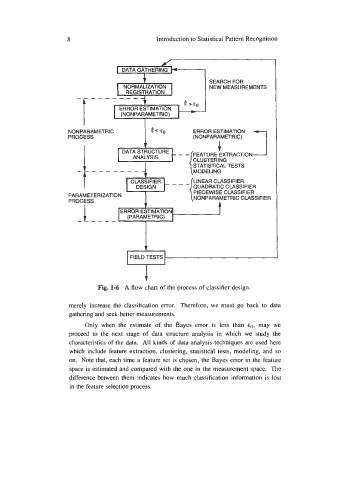
Fig. 1-6 A flow chart of the process of classifier design.
merely increase the classification error. Therefore, we must go back to data
gathering and seek better measurements.
Only when the estimate of the Bayes error is less than E,,, may we
proceed to the next stage of data structure analysis in which we study the
characteristics of the data. All kinds of data analysis techniques are used here
which include feature extraction, clustering, statistical tests, modeling, and so
on. Note that, each time a feature set is chosen, the Bayes error in the feature
space is estimated and compared with the one in the measurement space. The
difference between them indicates how much classification information is lost
in the feature selection process.