
Page 223 - Innovations in Intelligent Machines
P. 223
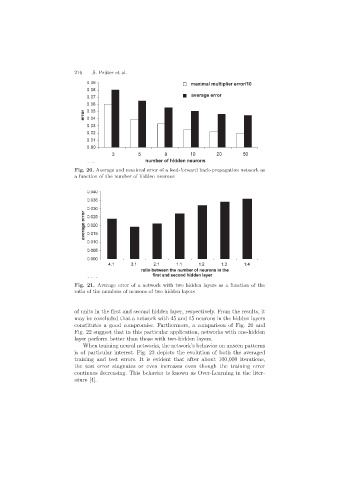
216 S. Pr¨uter et al.
error
Fig. 20. Average and maximal error of a feed-forward back-propagation network as
a function of the number of hidden neurons
average error
Fig. 21. Average error of a network with two hidden layers as a function of the
ratio of the numbers of neurons of two hidden layers
of units in the first and second hidden layer, respectively. From the results, it
may be concluded that a network with 45 and 15 neurons in the hidden layers
constitutes a good compromise. Furthermore, a comparison of Fig. 20 and
Fig. 22 suggest that in this particular application, networks with one-hidden
layer perform better than those with two-hidden layers.
When training neural networks, the network’s behavior on unseen patterns
is of particular interest. Fig. 23 depicts the evolution of both the averaged
training and test errors. It is evident that after about 100,000 iterations,
the test error stagnates or even increases even though the training error
continues decreasing. This behavior is known as Over-Learning in the liter-
ature [4].