
Page 381 - Engineering Digital Design
P. 381
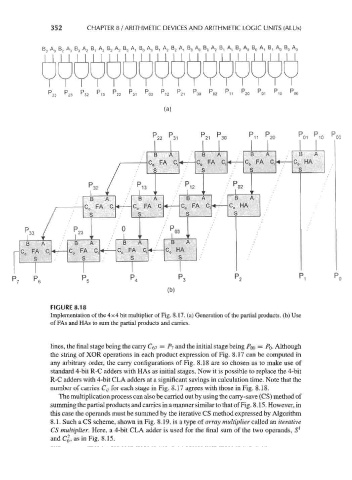
352 CHAPTER 8 / ARITHMETIC DEVICES AND ARITHMETIC LOGIC UNITS (ALUs)
B 3 A 3 B 2 A 3 B 3 A 2 B, A 3 B 2 A 2 B 3 A, B 0 A 3 B, A 2 B 2 A, B 3 A 0 B 0 A 2 B, A, B 2 A 0 B 0 A, B, A Q B 0 A Q
P P P r P r P r P r P r P r P r P r P r P r P P r P r P
r
r
33 23 ^32 13 22 31 03 12 21 30 02 11 20 ~01 lO OO
P P P
r r r
01 10 OO
P r P
r
1 O
(b)
FIGURE 8.18
Implementation of the 4x4 bit multiplier of Fig. 8.17. (a) Generation of the partial products, (b) Use
of FAs and HAs to sum the partial products and carries.
lines, the final stage being the carry Ce? = PI and the initial stage being PQQ = PQ. Although
the string of XOR operations in each product expression of Fig. 8.17 can be computed in
any arbitrary order, the carry configurations of Fig. 8.18 are so chosen as to make use of
standard 4-bit R-C adders with HAs as initial stages. Now it is possible to replace the 4-bit
R-C adders with 4-bit CLA adders at a significant savings in calculation time. Note that the
number of carries C// for each stage in Fig. 8.17 agrees with those in Fig. 8.18.
The multiplication process can also be carried out by using the carry-save (CS) method of
summing the partial products and carries in a manner similar to that of Fig. 8.15. However, in
this case the operands must be summed by the iterative CS method expressed by Algorithm
8.1. Such a CS scheme, shown in Fig. 8.19, is a type of array multiplier called an iterative
CS multiplier. Here, a 4-bit CLA adder is used for the final sum of the two operands, S l
and CQ, as in Fig. 8.15.